Machine Learning, Deep Learning e IA, ¿por qué todo el mundo habla de ello?
Desde que éramos niños, el cine y las películas de ciencia ficción, nos han estado intentando explicar que la Inteligencia Artificial (IA) un día llegaría a nuestras vidas para revolucionarlas.

También, el que los robots sustituirían a los humanos en sus trabajos y que, según muchas de estas películas, al final de todo el proceso, estos nuevos seres inteligentes se volverían contra nosotros y acabarían con nuestra especie. Así pues, ¿podríamos afirmar que la Inteligencia Artificial ya es una realidad? parece que sí. Y ¿pasará entonces lo que auguraban estas películas? Bueno, no exactamente (o al menos, no de momento).
Aunque es cierto que términos como el de Inteligencia Artificial llevamos escuchándolos muchos años en el cine, la explicación cinematográfica de esta no es digamos … tan “sexy” todavía.
Sin embargo, si podemos hablar, y tenemos multitud de ejemplos desde hace tiempo, de la Inteligencia Artificial Aplicada a un propósito, es decir, dotar a un sistema de la capacidad de resolver un tipo de problema concreto. Ejemplos de este tipo serían desde la famosa maquina Deep Blue que ganó en 1997 al campeón de ajedrez Kasparov, pasando por el robot que repite una misma acción en una cadena de montaje, hasta los asistentes de hoy como Siri, el sistema de recomendaciones de Netflix o las plataformas de detección y reconocimiento facial de Facebook o Google.
Una vez sabemos de que tipo de Inteligencia Artificial estamos hablando, lo siguiente es conocer las formas que tenemos de “enseñar” a nuestro sistema. Y aquí es donde aparece el famoso Machine Learning del que tanto habla todo el mundo.
Aunque suene a término súper moderno, el llamado Machine Learning como tal no es otra cosa que la rama de la Inteligencia Artificial orientada a la fase de aprendizaje de la máquina. Es decir, la fase en la que vamos a enseñar a nuestro sistema en qué basarse para tomar decisiones. Y es que precisamente en su propia definición es donde reside la principal diferencia en los diferentes tipos de Machine Learning (y en el por qué estamos escribiendo este artículo). Ya que vamos a encontrar grandes diferencias de rendimiento y precisión entre lo que vamos a llamar Machine Learning tradicional, basado en árboles de decisión y que podría asemejarse a las formas de programación más comunes, y lo que se conoce como Deep Learning.
Son muchos los medios y fabricantes de diferentes sectores que vienen hablando del Machine Learning, del Deep Learning y/o Deep Intelligence. Pero, ¿en qué se diferencian el Machine Learning y el Deep Learning y cómo pueden emplearse en el mundo de la Ciberseguridad?
Como decíamos, cuando hablamos de Machine Learning (a secas) a lo que nos referimos comúnmente es a la metodología de Machine Learning tradicional, basada en sistemas o árboles de decisión lineales y cuyas miles de variantes se vienen usando durante años en entornos de computación automatizada.
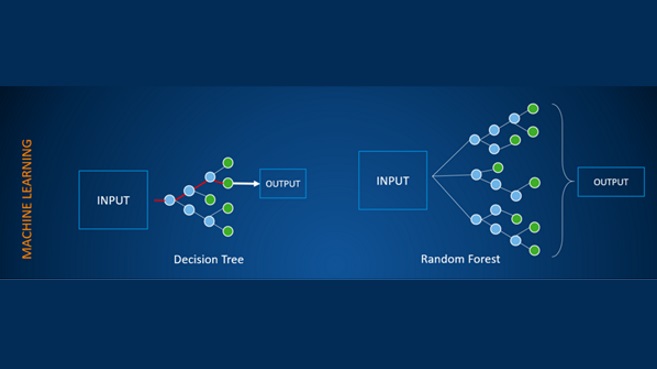
Si bien es cierto que los sistemas de decisión lineales pueden llegar a alcanzar una gran complejidad y ser altamente efectivos, por ejemplo, en tareas de clasificación e identificación básicas, estos comienzan a presentar problemas de rendimiento y precisión cuando esta tarea se vuelve más compleja. Un sistema de Machine Learning tradicional, donde el número de variables y el volumen de muestras a analizar comience a ser demasiado elevado, perderá de manera exponencial su precisión y efectividad, necesitando de un gran volumen de recursos para poder mantener unos tiempos de decisión aceptables. Los problemas no son menos si hablamos del mantenimiento del modelo. En este caso, el hecho de tener cada vez más datos con los que mejorar nuestro modelo de decisión, no supondrá una ventaja sino todo lo contrario, ya que el tiempo y esfuerzo que vamos a necesitar para procesar estos datos implicará un complicado reto y sobreesfuerzo excepcional por parte de sus programadores, debido a que cada dato va a necesitar pasar por todos y cada uno de los filtros hasta llegar a la salida.
Todos estos problemas de escalabilidad han hecho que, aunque el concepto de Machine Learning tuviera un gran potencial ya en su comienzo, no haya sido hasta la aparición de la variante del Deep Learning como solución a estos problemas (y por qué no decirlo, su adopción por parte de grandes corporaciones como Facebook o Google aplicándolo entre otros usos a sus sistemas de clasificación de imágenes), cuando todo el mundo ha comenzado a hablar de estas tecnologías.
El Deep Learning, y su variante de uso de redes neuronales en nuestro caso, como solución a los problemas de identificación y clasificación complejos, consiste en intentar imitar la forma en la que un cerebro humano aprende, es decir, sustituir el sistema de identificación por etiquetas, por un sistema de autoaprendizaje a partir del ejemplo.
Con Deep Learning, la forma de entrenamiento será dotar al sistema de un gran volumen de datos a partir de los cuales esperamos obtener una respuesta concreta. El sistema, formado por diferentes capas de “neuronas” interconectadas y que funcionarán en paralelo, descompondrá la información en busca de detalles estadísticos y será capaz de llegar a reconocer automáticamente cuáles son los valores que le llevan a un resultado concreto.
Vamos a poner un ejemplo más sencillo. Pensemos en una persona a la que conocemos a la perfección, un amigo, un hermano, nuestra pareja, o nuestro padre o madre, por ejemplo, alguien a quien reconoceríamos simplemente por un gesto, la forma de andar o la silueta, incluso aunque estuviera disfrazado, sin ni siquiera ver su cara. Ahora pensemos que tuviéramos que buscar e identificar a esa persona entre otras miles. Si fuéramos nosotros mismos los que buscáramos, seguramente en poco tiempo lo habríamos localizado sin lugar a fallo. Ahora bien, ¿que pasaría si tuviéramos que enseñar a alguien como encontrarlo? Podríamos dar a esa persona multitud de detalles, datos que consideraríamos vitales e incluso pasar horas dándole información adicional seguramente no necesaria, pero … ¿quién creéis que reconocería más rápido y con una mayor probabilidad de acierto a quien estamos buscando? La respuesta parece clara, ¿no?
El motivo de que nuestra capacidad de reconocimiento en este ejemplo sea mucho mayor es que nuestro cerebro ha estado años recogiendo millones de muestras de esa persona (entrenamiento) a partir de las cuales ha desarrollado la capacidad de identificar únicamente aquellos datos cruciales que necesita (modelo). Por mucho que quisiéramos explicar a un tercero qué detalles tendría que buscar (etiquetas), éste tendría que ir sujeto por sujeto, evaluando si cumple o no con cada uno de los patrones de búsqueda. Tomándose mucho más tiempo, equivocándose varias veces y haciendo necesario reconsiderar constantemente la combinación de los datos que le habíamos dado inicialmente.
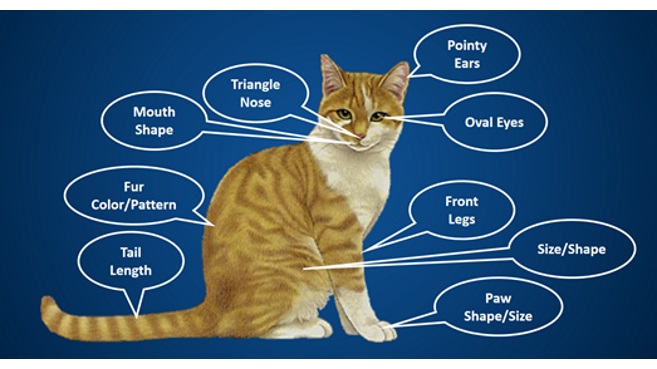
Machine Learning Feature Extraction
Al igual que ocurre en los modelos de Deep Learning, cuando en nuestro cerebro aprendemos a diferenciar elementos, inconscientemente vamos extrayendo por separado diferentes partes de ese elemento, color, textura, forma, etc. En cada caso estas partes tendrán una importancia o peso estadístico diferente a la hora de determinar si ese elemento es el que estamos buscando.
Cuando se nos presenta un nuevo elemento, nuestro cerebro lo descompone en esas pequeñas partes y evalúa por separado cada una de ellas utilizando diferentes capas de neuronas y fases de evaluación que le van a permitir ir deduciendo si el elemento cumple con uno u otro modelo.
Cuanto más entrenemos, es decir, más muestras añadamos a nuestro sistema, más eficiente será nuestra capacidad de deducción.
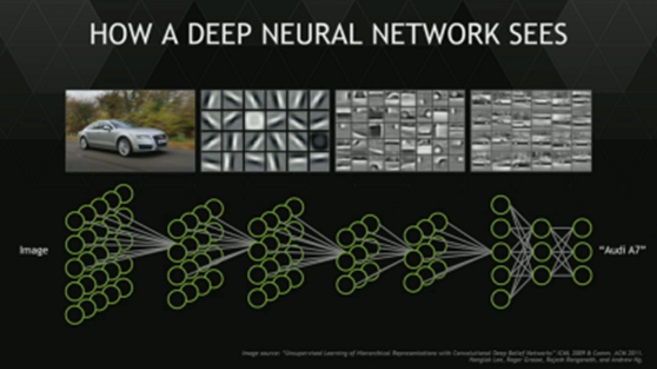
Deep Learning Feature Extraction
Precisamente el ejemplo nos resulta válido debido a que el principal uso de los algoritmos de Deep Learning reside en la identificación y clasificación. Ya sea de imágenes, como este caso, o de cualquier otro tipo.
En el campo de la ciberseguridad, vamos a poder aplicar la misma lógica, por ejemplo, en la búsqueda de malware. Tal y como ocurre en el caso de la identificación de imágenes, si contamos con el suficiente número de muestras para poder entrenar a nuestro modelo, podremos obtener un modelo de clasificación capaz de reconocer nuevas variantes de malware, aún no registradas en firma de detección, con una altísima tasa de acierto y una tasa ínfima de falso positivo.

En el caso de Sophos, tenemos a nuestra disposición millones y millones de muestras almacenadas durante más de 30 años (y que continúan creciendo cada día), analizadas, verificadas y clasificadas por nuestros laboratorios como software malicioso. Gracias a esto, podemos, por tanto, entrenar un modelo asegurándonos en todo momento que la información utilizada como fuente es totalmente fiable y no ha sido alterada.
Entonces, ¿podríamos decir que el ML no es algo nuevo?
Efectivamente: no lo es. Las técnicas de Machine Learning o aprendizaje de máquina se vienen empleando desde los primeros proyectos de programación, e incluso se utilizan de manera muy productiva en entornos con gran capacidad de computación, como son los servicios en nube. La diferencia en este caso es que, con la aparición del Deep Learning, hemos conseguido que ese aprendizaje automático a partir de un gran volumen de datos sea real (y no influenciado por la percepción humana) y los modelos obtenidos sean tan livianos que podemos incorporarlos a un PC de usuario con una tasa de acierto y capacidad de escalado muy superior, junto a una tasa de falsos positivos muy por debajo de los modelos tradicionales de Machine Learning.
Vale, pero entonces, ¿qué ventajas tiene el Deep Learning?
Si aún te haces esta pregunta, y resumiendo lo anterior en tan solo unas líneas, podríamos responder de este modo. En Machine Learning Tradicional, la clasificación de un elemento tiene que seguir linealmente todo el árbol de decisión. A causa de esto, cuanto mayor sea el número de variantes que contiene este árbol, mayor será el volumen ocupado por el modelo y mayor será el tiempo de análisis, será por tanto más grande y más lento. En cambio, en un modelo de Deep Learning, dado que el análisis se realiza de manera simultánea por las diferentes “neuronas” y que el resultado de éste se comparte entre las diferentes capas, el hecho de añadir una nueva condición apenas afectará al tamaño del modelo. Pero no solo eso, ante un volumen de decenas de millones de datos, como ocurre en el mundo real, en Internet, o en el llamado Big Data, un modelo de Deep Learning perfeccionará su tasa de detección tanto con cada acierto como con cada fallo, siendo cada vez más preciso y liviano. Mientras que en el caso del Machine Learning, el hecho de tener un gran volumen de datos con los que entrenar al sistema, no solamente no es una ventaja, sino que supondrá una carga superior de trabajo y un beneficio muy costoso de aprovechar.
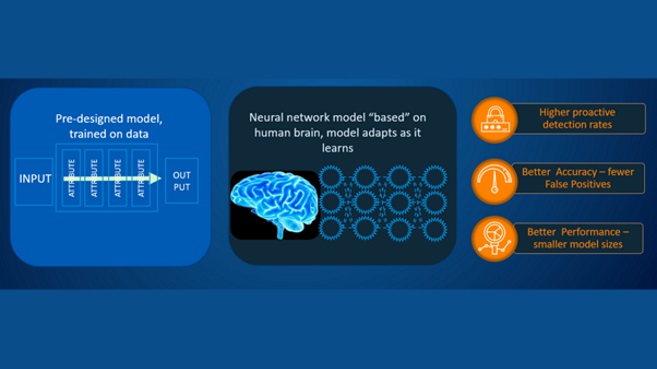
Por parte de Sophos, tras la apuesta en la adquisición el pasado año de una de las compañías americanas líderes en el desarrollo de algoritmos de Deep Learning, y propietaria de numerosas patentes al respecto, INVINCEA, los resultados no han podido ser más concluyentes.
Comparando modelos de detección con ambas tecnologías, se registraron unos tiempos de decisión de entre 20 y 100 milisegundos con su agente basado en Deep Learning, frente a tiempos 5 veces más lentos con el sistema de Machine Learning Tradicional. Así mismo, frente a los 20MB que llegó a ocupar este nuevo modelo en memoria, un sistema con similar nivel de acierto (que no de fallo) basado en Machine Learning elevó esta cifra entre los 500MB y 10GB de espacio. Si hablamos de falsos positivos, es decir detecciones erróneas, el resultado fue igualmente apabullante, registrando mil veces más fallos de identificación en el sistema tradicional.
En resumen, para una misma tasa de acierto, un modelo de Deep Learning, será más ligero, cometerá menos errores y será más rápido que un modelo basado en Machine Learning tradicional.
Es un artículo realizado por Iván Mateos Pascual, Presales Engineer de Sophos Iberia.























